
Key Takeaways
- Data Hub View: Aggregate bank, card, wallet, and investment feeds into one clean dashboard for faster decisions now.
- Real-Time Sync: Use secure APIs and AI pipelines to refresh balances, transactions, and insights with less delay now.
- Cleaner Signals: Normalize messy feeds into categorized, enriched, decision-ready data users can trust every day with AI.
- Secure Sharing: Support consent-based access, open banking compliance, and lower credential-sharing risks at scale now.
- Fraud Detection: Monitor transaction patterns with AI to flag anomalies early and reduce financial losses quickly now.
- Personalized CX: Turn financial behavior into tailored budgeting, savings, lending, and wealth experiences today with AI.
AI-driven financial data aggregation software development is the engine behind modern FinTech experiences because when your users’ money lives across multiple banks, cards, wallets, and investment accounts, “one dashboard” only works if you can unify that chaos. In practice, this is where AI-driven financial data aggregation software development thinking pays off: you’re not just collecting data, you’re turning messy provider feeds into clean, usable signals.
So, what does financial data aggregation mean in fintech? Simply put, it’s the process of gathering financial information from multiple sources and presenting it in a consistent, queryable format for analytics, budgeting, risk monitoring, and reporting.
To make it real, here are the main types of financial data you typically aggregate:
- Banking data (balances, accounts, transfers, statements)
- Transaction data (card purchases, ACH transfers, merchant lines)
- Investment data (holdings, trades, cost basis, performance snapshots)
Why is unified data access critical for modern platforms? Because most FinTech value is created when data becomes actionable like recognizing spending patterns, reconciling cashflow, or calculating risk exposure. When data is fragmented, teams end up with brittle spreadsheets, delayed insights, and manual reconciliation that scales poorly.
Traditional aggregation systems usually struggle with:
- Rigid parsing rules that break when providers change formats
- Slow updates (which kills “real-time” user expectations)
- Limited normalization, resulting in duplicate merchants and inconsistent categories
- Weak handling of edge cases (refunds, reversals, partial settlements)
How AI Enhances Data Aggregation Systems
AI for automated data extraction and normalization
AI improves aggregation by doing what rule-based systems can’t: adapting to variation. Instead of hard-coding transformations for every bank, card network, or wallet, you let models learn patterns and recover structure even when formats drift.
Key AI capabilities in AI in financial data processing include:
- Automated data extraction and normalization (turning fields into consistent schemas)
- Machine learning for pattern recognition across diverse data sources
- Intelligent categorization of financial transactions (with context, not just keywords)
- Real-time data synchronization and updates (so reports don’t go stale)
- Predictive insights from aggregated datasets (budgets, cashflow forecasts, anomaly risk)
This is where financial data aggregation software starts to feel “alive.” Users see cleaner categories, more accurate totals, and fewer weird gaps—while your backend becomes easier to maintain as new providers come online.
Key Features of AI-Driven Aggregation Software
Multi-source data integration (banks, APIs, wallets)
If you want a fintech data aggregation platform that users trust, features need to map directly to what breaks in real life: messy input, missing fields, delayed updates, and permissions complexity.
Strong AI-driven data aggregation software should include:
- Multi-source data integration (banks, APIs, wallets, and other account types)
- Real-time data processing and updates (or at least near-real-time freshness)
- AI-based data cleansing and normalization (dedupe merchants, reconcile fields)
- Smart tagging and categorization engine (spending, income, transfers, investing)
- Custom dashboards and reporting tools (portfolio views, cashflow views, insights)
- Secure user authentication and consent management (so sharing is explicit and controllable)
A practical way to scope these features is to think like an architect: integrations are not “modules,” they’re ongoing data relationships. That’s why financial data integration software should be designed for change, not only for launch.
Suggested table placement: Insert the table right after this feature list (end of this H3 section). Choose one title from the options below.
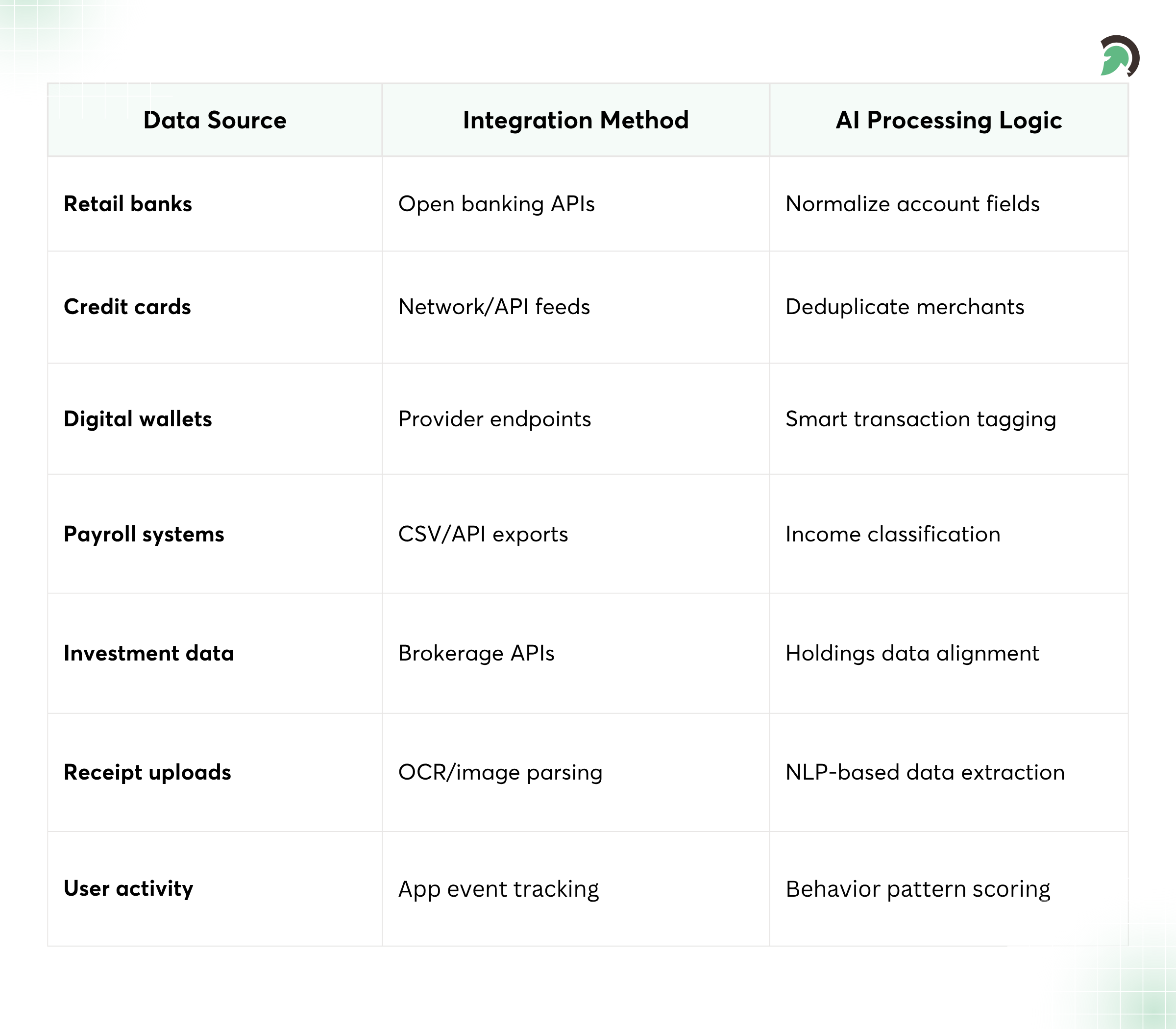
Multi-Source Financial Data Aggregation Framework
Core Architecture of Data Aggregation Platforms
Data ingestion layer (APIs, open banking feeds)
Architecture is where most teams either unlock scale or lock themselves into rework. A solid fintech data integration design separates concerns: ingestion, transformation, intelligence, storage, and exposure.
Here’s the core architecture pattern you’ll see in production-grade platforms:
- Data ingestion layer: provider APIs, open banking feeds, webhooks, batch pulls
- Data processing & transformation engine: schema mapping, deduplication, enrichment, reconciliation
- AI analytics & intelligence layer: extraction, categorization, risk signals, recommendations
- Storage & data management: normalized stores + raw audit logs for traceability
- API layer for third-party access: secure endpoints for your UI and partners
If your platform targets open banking data aggregation, treat open banking integration as a first-class domain. Consent, scopes, token lifetimes, and data freshness are not “edge details” they’re core behavior.
Step-by-Step Development Process
Define aggregation goals and user use cases
Think of development as a loop: define outcomes, build reliable ingestion, then apply intelligence, and finally validate quality at scale. Skipping steps here leads to “demo dashboards” that fail the first time real provider data shows up.
Use this workflow for AI-driven financial data aggregation software development-5 execution:
- Define aggregation goals and user use cases (budgeting, portfolio views, fraud/risk monitoring)
- Identify financial data sources and APIs (including fallback strategies)
- Design scalable and secure system architecture (queues, idempotency, audit trails)
- Develop backend pipelines for data ingestion (real-time where possible)
- Integrate AI models for data processing (parsing → normalization → categorization)
- Build frontend dashboards and interfaces (clarity beats complexity)
- Implement security and compliance measures (consent, encryption, access controls)
- Test for performance, accuracy, and scalability (load tests + data quality tests)
- Deploy and monitor system performance (freshness, error rates, model drift)
Internal link ideas to include in your site content (use as anchor text in relevant pages): fintech software development, payment processing systems, risk management software, financial analytics platforms, open banking integration.
AI Models Used in Data Aggregation
Natural language processing for financial data parsing
AI models in aggregation are usually less about “chatbots” and more about precision: extracting the right fields, classifying transactions consistently, and flagging what doesn’t fit.
Common model types include:
- Natural language processing for financial data parsing (merchant names, notes, line items)
- Classification models for transaction categorization (spend vs income vs transfer vs investing)
- Anomaly detection for unusual data patterns (unexpected reversals, duplicate charges, spikes)
- Recommendation models for financial insights (budget suggestions, watchlists, next-best actions)
- Continuous learning models that improve accuracy as your labeling feedback grows
When you design these models for AI in financial data processing, you’ll want explainability where it matters especially for categorization confidence and “why” behind anomalies.
Suggested table placement: Add this table after the model list (end of this H3 section). Choose one title from the options below.
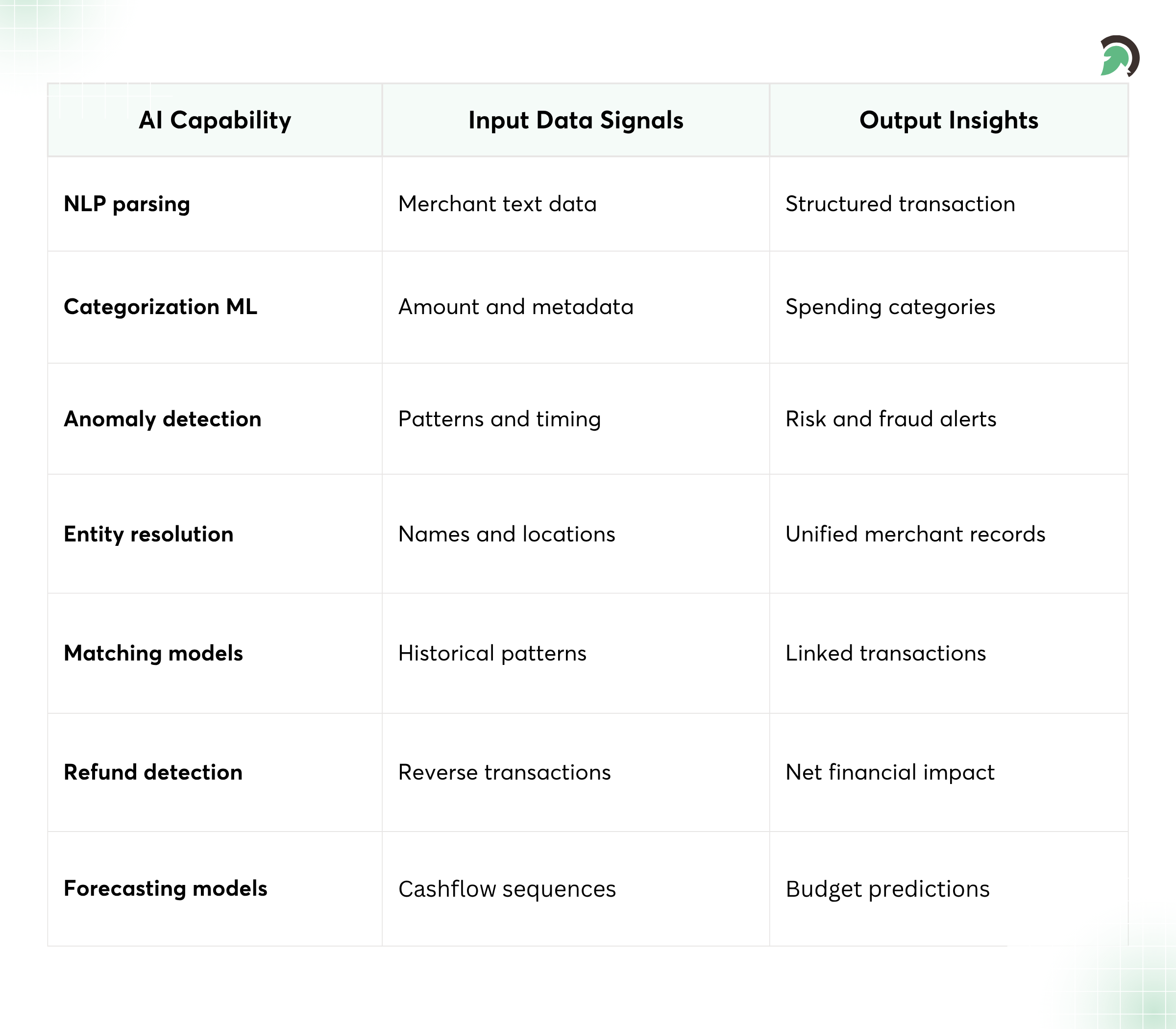
AI Capabilities in FinTech Data Aggregation
Technology Stack for Aggregation Software
Frontend: React, Vue
The stack should support two realities at once: high-throughput data pipelines and user-friendly reporting. A common approach is to combine reliable backend orchestration with ML tooling that can evolve safely.
Here’s a pragmatic technology stack for AI-driven aggregation projects:
- Frontend: React, Vue (dashboard experiences, consent screens, reports)
- Backend: Python, Node.js (services, integrations, APIs)
- AI/ML: TensorFlow, Scikit-learn (categorization, anomaly models)
- Data processing: Apache Spark, Kafka (streaming and batch transformations)
- Databases: PostgreSQL, MongoDB (normalized stores + document models)
- Cloud: AWS, Azure, GCP (scaling, monitoring, secrets management)
- Open banking APIs and providers: tokenized access feeds for open banking data aggregation
When teams choose this pattern, AI-driven financial data aggregation software development-5 becomes more maintainable: pipelines evolve, while your UI remains stable and your data contracts stay predictable. It’s especially helpful for fintech analytics platform experiences where users expect fast loading and accurate drill-downs.
Security and Compliance Considerations
Data encryption and secure storage practices
Security isn’t a checklist you finish at the end it’s architecture. Aggregation platforms handle sensitive financial data, so you must design for encryption, access control, and auditability from day one.
Core considerations include:
- Data encryption and secure storage practices (at rest and in transit)
- OAuth and secure API authentication (short-lived tokens, scoped permissions)
- GDPR and data privacy compliance (data minimization, lawful basis)
- Consent-based data sharing frameworks (users control what’s shared)
- PCI DSS where applicable (especially if you touch payment processing systems data paths)
Also, be deliberate about open banking integration: tokens, scopes, and refresh workflows should be auditable and automatically revoked when consent changes.
Suggested table placement: Add this table immediately after the security checklist above. Choose one title from the options below.
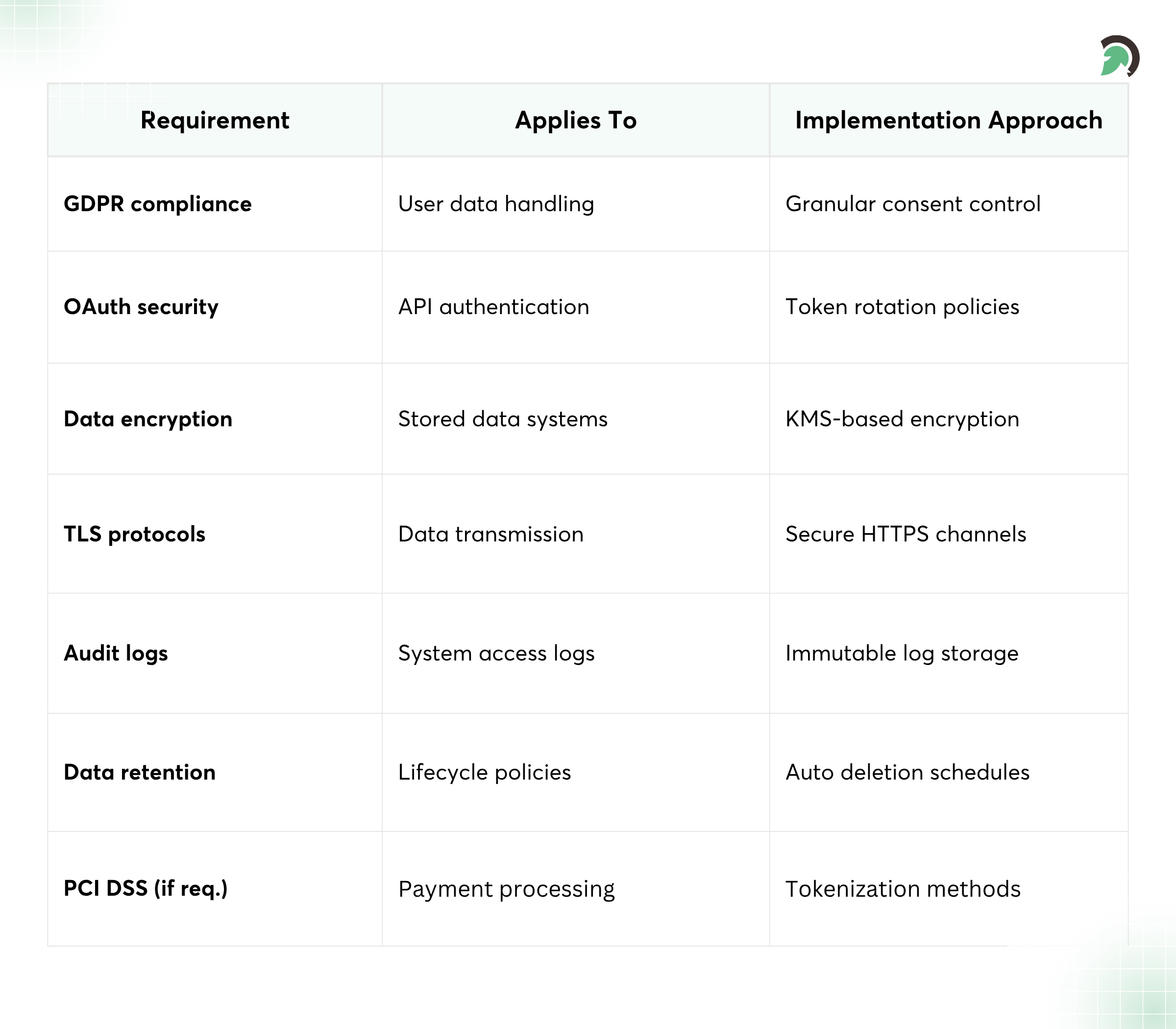
Financial Data Protection and Compliance Table
Challenges in Financial Data Aggregation
Inconsistent API standards across providers
Even with AI, aggregation is still integration work. The biggest challenges usually look boring but they cost real time when ignored.
Expect issues such as:
- Inconsistent API standards across providers (different fields, naming, pagination)
- Data quality and formatting issues (missing merchant details, timezone mismatches)
- Real-time synchronization challenges (webhook delays, rate limits)
- Managing user consent and permissions (revokes, scope changes, re-auth)
- Handling large-scale data volumes (backfills, long transaction histories)
This is why payment processing systems and card-driven feeds demand extra reconciliation logic; otherwise, your dashboards will look “wrong” even when the source data is technically accurate.
Best Practices for AI-Driven Aggregation Systems
Standardize data formats across sources
If you want your aggregation system to stay reliable as you add integrations, follow patterns that keep your data contracts stable and your models measurable.
- Standardize data formats across sources (build canonical schemas early)
- Use AI for continuous data validation (detect drift and parsing failures)
- Build a scalable microservices architecture (separate ingestion from intelligence)
- Monitor API performance and uptime (freshness SLAs and error budgets)
- Ensure transparent user data handling (clear consent UX and data export)
Done well, your financial data integration software becomes a durable foundation for fintech analytics platform reporting without the constant rebuild cycle.
Benefits of AI-Based Data Aggregation
Unified view of financial data
Once aggregation is reliable, the benefits show up immediately in both product quality and internal efficiency.
Key advantages include:
- Unified view of financial data (balances, cashflow, spending, holdings)
- Faster and more accurate decision-making (especially for risk monitoring)
- Improved user experience through insights (better categories, fewer anomalies)
- Reduced manual data handling (less reconciliation work for teams)
- Scalable and flexible infrastructure for new providers
Most teams also find that fintech analytics platform features like drill-downs and custom reports work better when categorization and normalization are handled consistently by the underlying AI-driven pipelines.
If you’re choosing between “basic” and advanced financial data aggregation software, look at what happens after the first month. AI-based systems help because they keep learning and adapting to changes in providers.
Cost Factors and Development Timeline
Number of integrations and APIs
Cost comes from complexity. It’s not just how many endpoints you connect it’s how clean, consistent, and secure your aggregation workflow must be.
Major cost factors typically include:
- Number of integrations and APIs (bank + card + wallet + investment coverage)
- Complexity of AI models (training, labeling, evaluation pipelines)
- Data storage and processing requirements (raw audit retention + normalized stores)
- Security and compliance implementation (consent flows, encryption, logging)
- MVP vs full-scale platform scope (how deep analytics needs to go)
As a rough rule of thumb, MVP timelines stretch when you include multiple regions, multiple provider types, and strict reporting accuracy requirements. Plan your MVP around the highest-value use case, then expand into broader open banking data aggregation coverage in phases.
And yes—integrating open banking data aggregation can be straightforward until you hit edge cases (partial reversals, inconsistent transaction codes, and refresh interruptions). That’s normal, but it’s also where budgets go.
Future Trends in Financial Data Aggregation
Open banking ecosystem expansion
The aggregation landscape is evolving fast, and the platforms that win will treat “data freshness + intelligence + trust” as a single product experience.
Notable trends to watch:
- Open banking ecosystem expansion (more providers, more standards variance)
- AI-driven personal finance insights (recommendations that adapt to user behavior)
- Embedded finance integrations (aggregation powering embedded wallets, lending, and spend controls)
- Real-time financial data ecosystems (streaming updates, event-driven views)
- Increased use of decentralized data systems (more emphasis on consent and user-controlled sharing)
Strategic Considerations for Businesses
Choosing the right data providers and APIs
Before you build, decide what “success” means for your users and your business model. Then align your aggregation roadmap accordingly.
Strategic points to keep in focus:
- Choosing the right data providers and APIs (coverage vs reliability)
- Ensuring scalability for growing data needs (backfills, performance, model evaluation)
- Aligning aggregation with business goals (what insights drive revenue financial data aggregation software, or retention)
- Partnering with fintech development experts (especially for compliance and integration risk)
If you’re planning fintech software development around a financial data integration software foundation, make sure your team can handle operational excellence: monitoring, data quality gates, and incident response for provider outages.
Internal linking suggestion: consider linking to pages that cover fintech software development, payment processing systems, and risk management software to help readers connect aggregation with your broader engineering services.
Conclusion
AI-driven financial data aggregation is changing how businesses work with financial information. Instead of scattered data and manual checks, teams can access cleaner insights, faster reporting, and more reliable decision-making from one connected system. For banks, fintechs, and enterprises, this means better risk evaluation, improved customer experiences, and stronger control over financial operations.
As digital finance continues to evolve, companies that invest in intelligent data aggregation will be better prepared for real-time analytics, fraud prevention, and personalized financial services. EvinceDev helps businesses build secure, scalable, and practical aggregation solutions aligned with their goals. To create a smarter financial ecosystem, explore AI-powered aggregation software that turns complex data into meaningful business value.


